
Technical Challenges in Implementing Hybrid Search - Part 2
Part 2 - Real-world challenges when implementing Semantic Search using OpenAI's text embedding model.

October 2023 - Ho Chi Minh City, Vietnam
While Generative AI could be a game changer, adapting it to your business case requires dedication and creativity. Let our team at Designer Journeys share our lessons learned using Generative AI to supercharge your search experience.
This is the second part of the four parts that Designer Journeys Techies share our practices and learnings after launching Generative Search, a complete revamp of our Search Experience that leverages text-embedding models and chat completion capability of OpenAI in combination with OpenSearch.
Check out our first part here: https://designerjourneystechie.substack.com/p/generative-ai-search-revamp
TL;DR
This post covers the following concepts
Text Embedding
Semantic Search
Why OpenAI’s text-embedding model is a supercharge to the existing Semantic Search technique
So, if any of these concepts are new to you, we’ve got you covered.
The riveting part is we will discuss the challenges during the process, including
Performance Optimization
Avoid Compression Loss
Combine text-based Lexical Search with vector-based Semantic Search for optimal results
Parts 3 and 4 will cover how we evaluate the search result relevance, address specific challenges to a travel marketplace, and prompt-engineer our new travel concierge Wanda.
Make a pot of tea and enjoy the post.
Overview of the architecture
At Designer Journeys, we like to build handcrafted trip plans for you to experience the world in extraordinary ways.
Therefore, our techie guys often practice drawing diagrams and flow by hand. And we select the most difficult-to-read handwriting to post so that no bot can understand. An example is our system architecture.

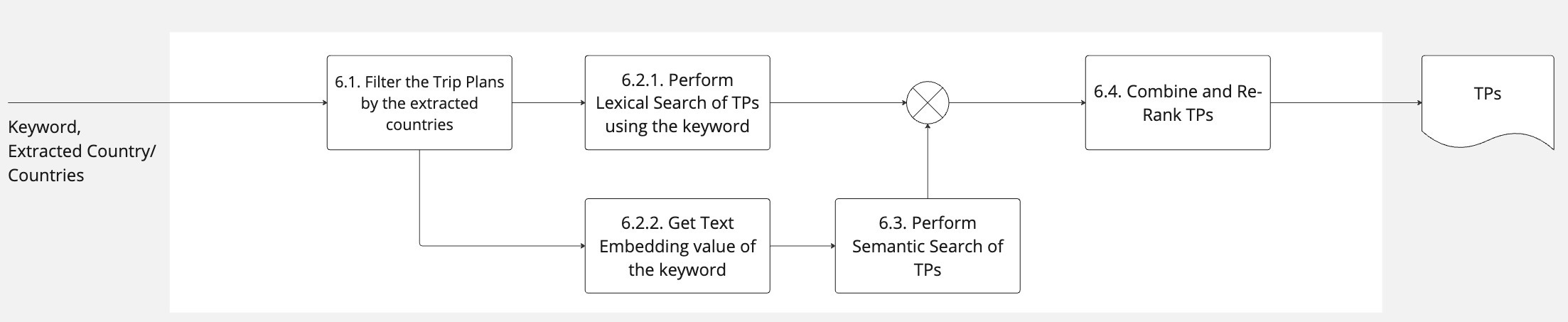
Specifically, the diagram below is an oversimplified version of the key steps to enable the Generative Search experience.

Below are the abbreviations with their meanings
TP = Trip Plan (a detailed itinerary built by one of our local designers. For instance, check out our 9-Day Authentic Samurai and Sake Experience).
LD = Local Designer (a local travel expert who helps our customers design their tailor-made trip plans and provides on-the-ground support for travelers. For instance, meet Nanami Granger, one of our local designers in Japan).
Flow Description
After having the search keyword, 2 steps are executed in parallel
[1.1] Call ChatGPT to generate travel insights based on the keyword.
[1.2+] Perform a series of next steps to retrieve the relevant trip plans with relevant local designers and travel guides. Specifically, depending on the keyword’s type, different steps are taken.
If the keyword type is a destination (e.g., Tokyo, Kansai, Japan), there is no need to perform a complicated search here. Trip Plans to that destination are returned.
After the relevant trip plans are returned, the related local designers are returned and presented in the 2nd tab of the Search Result Listing page.
Next, the system seeks relevant travel guides and blog posts.
If the keyword is not a specific destination, the next step is to extract the country from the keyword. Why this step is here and how it is done will be described later.
After a country or a list of countries is extracted from the keyword, the system performs a series of steps to produce a list of the most relevant trip plans.
After the relevant trip plans are found, steps #3 and #4 are executed.
The final results are
A generative answer that communicates relevant travel insights;
A list of relevant trip plans;
A list of related local designers;
A list of relevant travel guides and blog posts.
Before diving into further details, let’s look at the end goal of which types of search queries we want to support.
What Types of Queries Can This Search Support?
Naturally, most of us think that the search queries are like this
or,
But those are at the low bar. We want something like this
11-day private Italy itinerary filled with unique, local experiences
to wineries, historic villages, the finest food, and Italian supercars
and,
Attend the Hatsumode, the first shrine visit of the year, in Japan
Unrealistic?
This was the first feedback from some of our team members when they heard the idea. Because with the majority of search engines, people are taught and forced to limit their questions to a few vital keywords or they won’t get any results.
But that does not mean we should limit ourselves to the status quo. People don’t know what they want until they experience it, right?
Below is a fraction of what our users looked for. These long and complex requests do not account for the majority of all search keywords though. However, we firmly believe in the freedom and power it offers and once, we have proved that we can deliver relevant results with accurate travel insights, people will be addicted to it.

Sounds challenging? Let’s break it down. But first, let’s go through the concepts.
Text Embedding
Text Embedding is a technique used in Natural Language Processing (NLP) to convert text data into numerical vectors in a continuous vector space. This is achieved by mapping words, phrases, or entire documents into a high-dimensional space, where the vectors of semantically similar items have shorter distances.
The table below contains examples of how sentences are represented with numerical vectors.

In search applications, text embedding is invaluable.
By converting textual queries and documents into vectors, you can measure the similarity between them using techniques like cosine similarity. This allows for efficient and accurate retrieval of relevant information.
As a small example, below is a heatmap of an embedding containing 10 features for each sentence. By comparing the numerical values of all features, we would immediately spot that the three highlighted sentences have similar values and hence, pretty much have the same meaning.

For a more detailed explanation of Text Embedding, refer to this excellent article (with video) by Cohere: https://docs.cohere.com/docs/text-embeddings.
Semantic Search
Semantic search is a search technique that focuses on understanding the intent and context behind a user's query, rather than relying solely on keyword matching. It aims to retrieve conceptually relevant results, even if they don't contain the exact words from the query.
Semantic search leverages NLP and techniques like text embeddings to comprehend the meaning and relationships between words in a query and the documents being searched (in our case, the trip plans).
In contrast, lexical search, also known as keyword-based search, relies heavily on matching specific words or phrases in a query with those in the documents. It doesn't consider the broader meaning or context of the words used. This can lead to limitations in accurately retrieving relevant information, especially in cases where synonyms, related terms, or variations in language are common.
Confused?
Let’s first look at an example of what Semantic Search is not.
Query: Where is the World Cup?
Responses
The World Cup is in Qatar.
The sky is blue.
The bear lives in the woods.
An apple is a fruit.
With keyword search (or lexical search), the correct answer is retrieved by counting the number of common words between the query with each response*. The response with the most common words is the answer and in our case, it is “The World Cup is in Qatar.” (4 words in common).
This is the correct response but it won’t always be the case. Imagine that there is a 5th response to compare, “Where in the world is my cup of coffee?”
This new sentence has 5 words in common and hence, would win if it were in the list.
In contrast, Semantic Search describes each sentence with an embedding or a vector. In the case of our application that uses the model text-embedding-ada-002, it is a vector of 1536 numbers.
An essential characteristic of embedding is that similar sentences are assigned to similar vectors of numbers. Therefore, by measuring the distance between each pair of vectors and picking the response with the smallest distance to the query, Semantic Search can find the correct answer.
As we cannot visualize 1536 dimensions and for the sake of simplicity, we will use a 2-dimension graph to demonstrate the idea as below.

In this graph, each sentence is assigned to a pair of coordinates. The answer is located by calculating the distance between the query to each of the responses. As a result, “The World Cup is in Qatar” is the answer as it is the closest point to “Where is the World Cup” on the graph.
Simple?
In reality, it is much more complicated as we just have a bit over 1500 coordinates (or features) to compare. But it is feasible to do so by using one of these methods below
Dot Product Similarity
Cosine Similarity

Designer Journey uses Cosine Similarity which will calculate the relative angle between two vectors and hence, return a value between 0 and 1. The higher the value, the smaller the angle is, and therefore, the closer their meanings are.

Imagine we have a dataset of 8 sentences, their similarities are represented in a plot below.
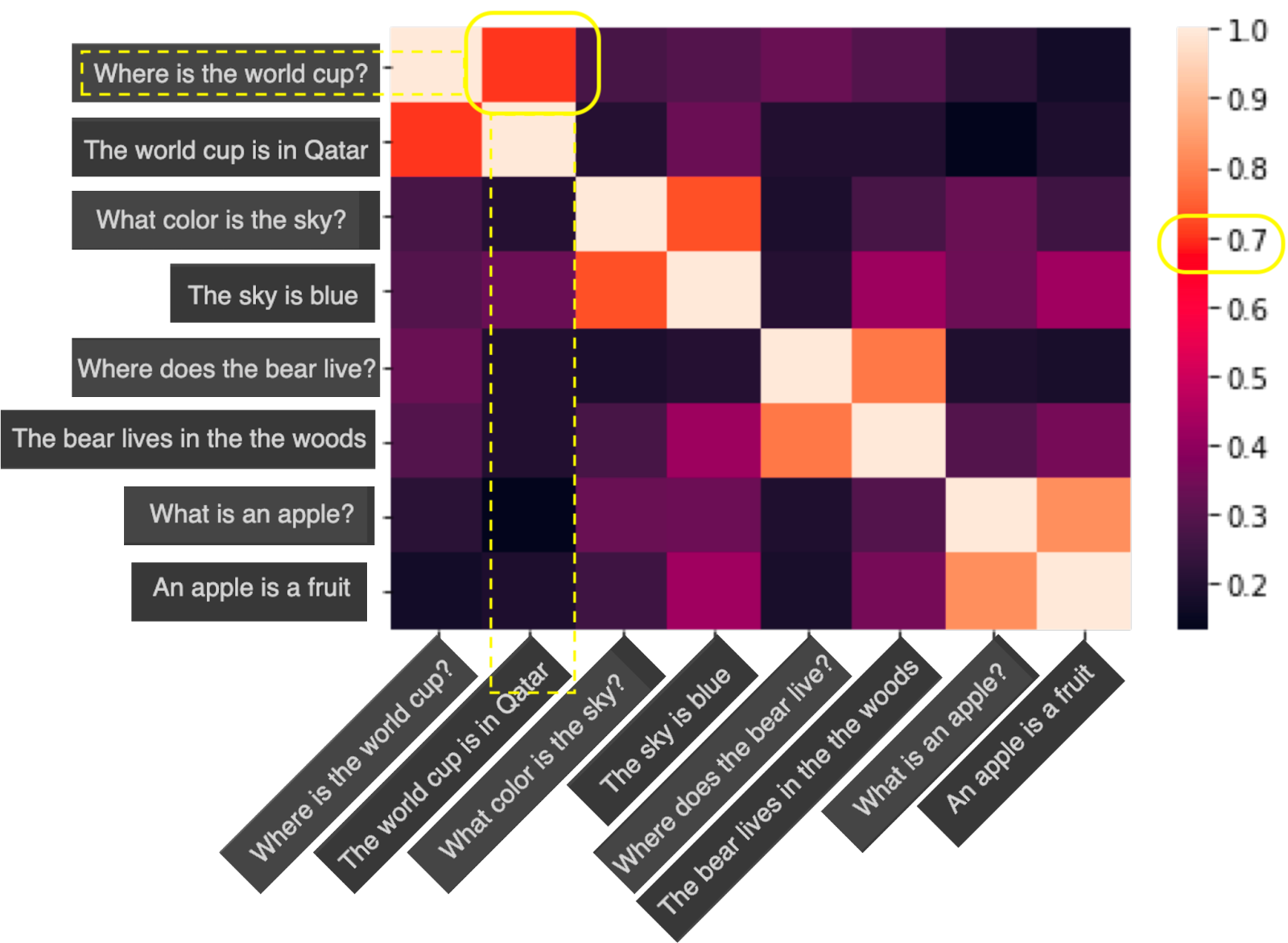
As you can see, except when comparing the query to itself, “The World Cup is in Qatar” has the highest similarity value which is around 0.7, and therefore, it is the answer.
Isn’t it beautiful? A complicated problem is resolved with a novel yet simple solution.
However, there are still challenges with Semantic Search implementation; including
The method to embed text (or to produce the vectors of numbers we’ve been talking about);
How to optimize for performance with big datasets;
How to avoid the potential of compression loss when representing complex, high-dimensional textual data in a lower-dimensional vector space;
How to best handle the rare or specialized terms;
and so many other challenges
This is where OpenAI, OpenSearch, and Hybrid Search come in handy.
Keep reading!
(*): This is an oversimplified version.
The example above is a rephrased summary of this detailed explanation by Cohere: https://docs.cohere.com/docs/what-is-semantic-search - check it out.
Why are OpenAI Embedding Models a supercharge to Semantic Search?
According to this blog post,
OpenAI's new text-embedding model, text-embedding-ada-002, outperforms all previous embedding models on text search, code search, and sentence similarity while achieving equivalent performance on text classification.
By unifying the capabilities of five different models, the /embeddings endpoint's interface has been greatly simplified.
The new model also boasts a longer context length, and smaller embedding size, and is 90% cheaper than previous models of similar size, making it a more efficient and cost-effective choice for natural language processing tasks.
The text-embedding model is the cornerstone of Semantic Search and with the capability of text-embedding-ada-002, we simply cannot overlook it.
OpenSearch and OpenAI are a perfect match
Designer Journeys has been using OpenSearch, which is an open-source, distributed search and analytics engine platform, to serve most of its search use cases.
OpenSearch is well-known for its powerful keyword-based search methods. But it also offers semantic search seamlessly. Combining the power of OpenAI’s text-embedding model with OpenSearch, we were able to adopt the latest advancement in Generative AI to our platform within a week for the first demo.
Here’s a step-by-step of how it works
Use
text-embedding-ada-002to embed all of our trip plans.Index these embeddings in OpenSearch.
Whenever there is a search request, use that model to embed the query.
Use OpenSearch to perform a vector search using the query’s embedding and the indexed embeddings of trip plans.
Return the most relevant trip plans based on the cosine-similarity scores.
Looking for a detailed setup? Check the online demo here.
Moreover, OpenSearch elegantly resolves three of the key challenges for Semantic Search implementation
Performance Optimization;
Avoid Compression Loss;
Hybrid Search for more relevant results.
Performance Optimization
Let’s recall our example of a dataset of 8 sentences and the quest is to find the answer to the question “Where is the World Cup?”.

To identify the answer, we have to calculate all possible distances from the query to the responses. In this example, there are 8 distances to calculate (including the query itself).
Imagine if you have a dataset of millions or billions of records.
At Designer Journeys, we don’t have that much data yet but it’s already tens of thousands of trip plans we’re comparing**.
It is not feasible to perform an exhaustive search like that.
One of the options offered by OpenSearch is to use the Approximate-k-Nearest-Neighbors (Approximate k-NN). Commonly, there are two algorithms to achieve this type of search
Inverted File Index (IVD): Consists of clustering similar documents, and then searching in the clusters that are closest to the query.
Hierarchical Navigable Small World (HNSW): Consists on starting with a few points, and searching there. Then adding more points at each iteration, and searching in each new space.
To get started quickly, we are using HNSW which does not require any training upfront. It also provides a very good approximate nearest neighbor search at low latencies. However, the downside is that it can consume a large amount of memory.
To enable OpenSearch to use this method, simply set the configurations according to this documentation.
(**): we have around 2000 public trip plans for travelers’ inspiration but a couple of thousand other private trip plans customized for our customers.
Avoid Compression Loss
Compression Loss in Text Embedding refers to the reduction in information that occurs when converting text data into a compressed numerical representation. During this transformation, some nuanced details and context may be lost, as the model condenses the information into a more compact form.
This compression is a necessary trade-off to make the data manageable and efficient for processing.
To minimize the impact of compression loss, there are two actions to take
Using a well-designed text-embedding model, like OpenAI’s
text-embedding-ada-002. Well-designed text-embedding models strive to retain as much relevant semantic information as possible, allowing for accurate comparisons and meaningful retrieval of information in semantic search applications.Breaking a long document into smaller chunks of data so that the model doesn’t “compress” too much information into one vector.
Point #1 is obvious to us as we rely on the mentioned model. However, it is worth noting that you must use the same text-embedding model for the dataset embedding (trip plans, in our case) and the query embedding.
If for any reason, one day, you decide to switch to a different model, you cannot just embed the query with the new model and use the vector result to compare with the old embedding dataset. The whole dataset must be re-embedded and indexed. This is kind of obvious to some people but when we started, it was the question that took us some time to research.
Point #2 sounds easier than it is in practice. See one of the discussions here.
We don’t attempt to build a perfect version from the beginning.
So for Designer Journeys, we chose a simpler path so that we can release faster and learn faster.
Before we explain our choice, let’s look at the elements of a trip plan.
Metadata like title, summary, and highlights;
The list of countries that the trip plan covers as well as the breakdown of cities per day;
The travel themes (whether it is an adventure, culture & arts, cycling, or hiking & trekking trip);
The length of stay (or the trip’s duration);
The detailed itinerary for each day includes
The title and summary;
The accommodation;
The attractions and list of included activities during that day.
See one of our trip plans 9-Day Authentic Samurai and Sake Experience (Japan) to make it easier to understand.
The question for us was whether we embed all the details of a trip plan or break them into chunks. And if it is the latter, how should we break it down?
With the above trip plan of 9 days visiting Japan, the exported PDF contains 13 pages of text (see below for an extraction). With this super-long text, compression loss feels very real. Therefore, we discarded this option very quickly.

The conclusion quickly came down to splitting a trip plan into multiple chunks but how we split it is a tougher question.
We decided to run an experiment to test the accuracy with different variations. How we perform the testing will be covered later in this post but below are the options we ran through
Use the whole trip plan text (as shown above) and break it down into fixed-size chunks. In our case, we selected the size of text equal to 3072 tokens.
Use some of the trip plan’s features as chunks and the full itinerary is split into fixed-size chunks as in the first option.
In our experiments, we use these features as the chunks
Trip Title
Trip Summary. This includes the overview description of the trip as well as the list of inclusions and exclusions; for instance, whether the trip covers the entrance fees to the listed attractions, the airport transfers, and so on.
A combination of information served as the metadata
Length of stay
The list of cities and countries that the trip covers
The travel themes
Quickly, we realized that the second option offered greater flexibility as we could tweak and test different weights of different chunks. For instance, though a query might match some of the details mentioned in the itinerary, the first impression any users would have is the trip title. Therefore, having a higher weight for the title’s chunk ranks the trip plans with titles best matched in higher positions.
With the second option, we tested multiple variations; whether we use all chunks or omit any, whether we apply the same weight to all chunks or some will be seen as more important.
Before we move on to the winner variation, let us explain how the scoring works when there are multiple chunks.
In OpenSearch, when a document (trip plan, in our case) contains multiple chunks, the cosine similarity is calculated between the query vector and the vectors of each chunk of the document.
The scores from each chunk are aggregated to produce a final score for the entire document. The specific method of aggregation may vary depending on the implementation. Common methods include averaging, summing, or taking the maximum or minimum score. Check out the Metric Aggregations documentation for a full list of methods.
Single-value metric aggregations
Single-value metric aggregations return a single metric. For example,
sum,min,max,avg,cardinality, andvalue_count.
Our implementation uses the default aggregation method. Surprised? ;-)
This is actually because the default method is already good to go***. The final score is the product of the sum of all chunks’ scores and the minimum score of all chunks’ scores.
Talking is cheap hard to understand, show me the code.
const build_query = {
bool: {
must: [
{
bool: {
should: [
{
query_string: {
default_operator: 'OR',
query: dest_query,
fields: [`${f_dest}^${dest_weight}`],
},
},
{
query_string: {
query: query,
default_operator: 'OR',
fields: [`${f_name}^${name_weight}`],
},
},
],
},
},
{
nested: {
path: f_chunk,
query: {
function_score: {
query: {
query_string: {
default_field: `${f_chunk}.${f_content}`,
default_operator: 'OR',
query: query,
},
},
functions: [
{
script_score: {
script: {
source: 'cosineSimilarity(params.query_value, doc[params.field_vector])',
params: {
field_vector: `${f_chunk}.${f_vector}`,
query_value: this.query_vector,
},
},
},
weight: vector_weight,
},
],
},
},
},
},
],
},
};For debugging purposes (and learning purposes as well), you can turn on the explain mode so that, for every search request, OpenSearch explains how it calculates the score for each document. See the example below.

Note that, in both screenshots above, focus only on the highlighted blocks for the moment because there is a second part which we will explain shortly that we are combining lexical search and semantic search to produce the final results.
Moreover, the first screenshot is not the initial code that we tested but we’ll explain it because as you can see, in the final version, we don’t perform a semantic search on the trip title, the summary, or the list of cities and countries.
(***) Why do we have to consider both the sum of scores and the minimum score, you probably ask?
Let’s ask the reverse question, what will happen if we use only one of those metrics?
If only the sum of all scores is used, there is a chance that a moderately relevant but lengthy document might be ranked higher than a highly relevant but shorter one.
One significant factor that impacts the document length is the duration or the number of days a trip plan takes. While our trip plans’ durations are highly concentrated between 8 and 16 days, there are shorter trips like this 2-Day Kyoto Private Walking Tour (Japan) and longer trips like 24-Day Charms of Italy.
Therefore, accounting for the minimum score helps avoid potential biases that may arise from relying solely on the sum of scores. There are also other techniques to resolve this problem but after the test, we felt this default aggregation method is good enough.
Hybrid Search
The top 5 results for this query “Pu Luong trekking in Vietnam” when performing a semantic search are
While with lexical search, below are the top 5
If you’re like me, you had fallen in love with semantic search before this moment came ;-)
In the top 5 results produced by the semantic search, there is only one relevant result. The others are related to other destinations, for instance, Pù Bin (in Mai Chau, Hoa Binh, Vietnam, which is deemed semantically similar to Pù Luông (in Thanh Hoa, Vietnam).
What we have learned is that Lexical Search works very well if the keywords are accurate and specific while Semantic Search brings along some noises/distractions.
That was when the Hybrid Search, combining keyword-based lexical and vector-based semantic search came into play.
There are two decisions to make when switching to Hybrid Search. But before getting into the details, let’s see its top-5 results for the query “Pu Luong trekking in Vietnam”
All top 5 results are relevant! Awesome.
Now, back to the 2 decisions to make, they are
Should both search techniques be applied to similar features or each one should focus on a specific set of features?
How should we aggregate the results from both search techniques?
To answer the first question, we did a couple of experiments and evaluated the results. The experiments are in 2 categories
Perform both techniques on the similar features;
Test out different sets of features each technique focuses on.
Keeping in mind the strengths of each technique, we have landed on the approach below
Perform a keyword-based lexical search on features that are shorter and contain specific keywords that once matched, should be prioritized. They are the title and the list of cities and countries of a trip plan.
Perform a vector-based semantic search on features that are longer and generally, less efficient when performing the keyword search. They are the metadata and the itinerary of a trip plan.
You probably ask, why not perform both techniques on similar features? It seems easier to implement, right?
The answer is that while the approach we chose and the easier approach do not have a significant difference in search accuracy, the one we chose is faster and consumes fewer resources.
Below is the sample screenshot of the results returned with the explanation from OpenSearch

Aggregate the Results from Lexical and Semantic Search
The challenge with the combination is that they use non-comparable score types.
While we are using cosine similarity with Semantic Search, the lexical search uses BM25 as its scoring function.
While cosine similarity values run between 0 and 1, BM25 scores are unbound and non-evenly distributed.
For instance, see the BM25 value distribution of the MSRD dataset (28,320 unique movie search queries over a database of 10k TMDB movie descriptions) below.

While 90% of the time the highest score is below 10, the values of the other 10% are distributed on a larger range (from 10 to 40).
This means that, if we just take the score from Semantic Search and add it to the score of Lexical Search, Semantic Search would make a small difference.
There are lots of discussions on this topic but there seems to be no perfect solution. A sophisticated solution, for instance, Learning-to-Rank by Pinecone - which is a great solution theoretically, is difficult for self-implementation and difficult to start with.
So, we just decided to go with a naive approach, multiplying the cosine-similarity score by a weight before adding it to the BM25 score.
How we came up with the weight was by going through lots of experiments (you read it right ;) and the weight might not apply to your context. So, try it out and just pick one value to start with.
What's Next?
Well, my pot of tea is finished so let’s take a break here.
Parts 3 and 4 will cover how we evaluate the search result relevance, address specific challenges to a travel marketplace, and prompt-engineer our new travel concierge Wanda.
Feel free to hit us with any questions or suggestions.
Generative Search Series
Part 2 - Technical Challenges in Implementing Hybrid Search.
Part 3 - Search Result Evaluation
Part 4 - Wanda's Travel Insights
Our Techie Team at Designer Journeys
We have a simple mission that is “For you to experience the world in extraordinary ways”.

If you are familiar with the supply chain of multi-day tours, you will find it inefficient and expensive as there are lots of middle layers.
This is the major blocker to make extraordinary travel accessible to the majority of people.
Extraordinary can have different meanings for different people. For us, it means
You have the choice to experience the local experiences. You have access to the best-value pricing and a seamless booking experience.
You own your traveling pace.
You are taken care of every step of the way, from planning to booking, pre-trip, in-trip, and even post-trip.
You both learn something and make a small impact wherever you travel.
The way the supply chain is designed makes extraordinary travel a privilege for the rich.
Disrupting the supply chain is the only option and technology is the driver.
If you share the same mission, why not connect with us?